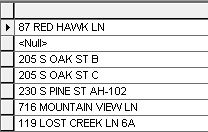
I have a feature class with parsed address fields and I need a single concatenated field. Some of the addresses have directionals like “N” or “S”, some have units, and some don’t. A simple expression will litter the field with extra spaces.
Parsed addresses
Here is a short Python snippet that uses string formatting & the Update Cursor to populate a field with only the relevant data for each record.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Fields returned by the cursor are accessed by index in the order they are listed in the list, so row[0] refers to the value in the STREETNO field, row[1] is the STREETDIR field, and so on.
A series of conditionals tests whether the “extra” fields have content, and successively builds the final concatenation expression using string formatting. Here I am using numbers for placeholders in the string formatting substitution, but it is not strictly necessary.
Line 25 sets the appropriate field (which has an index of 5) to this expression, and then line 26 calls “updateRow” to make the change.
As part of a larger set of scripts, I needed to check for unique values in a feature class field. There are a number of manual ways to do this in ArcGIS Desktop, but here is a snippet to create a list of non-unique values and print them to the console. You could also write them to a file, or incorporate the snippet into a fix for the issue.
The basic concept is a “list within a list”. The Search Cursor is the master “list” that gets iterated over, and then values get added either to a unique value list or a duplicate value list (if they already exist in the unique value list). To speed up the analysis, I set up the Search Cursor parameters so that it only uses a single field. I don’t need any geometry or other fields in order to analyze the unique values in one field.
String formatting gets used in a couple of places here, substituting the {0} in an output string with the value in parentheses after str.format(). The “str” in the string methods represents the string you are formatting or otherwise altering. Another string method, str.join(), is used to print the list values, in this case separated by a new line: “\n”.join(list). If you wanted commas, you could use “,”.join(list).
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
A few snippets for working with feature class fields.
The basic method of accessing fields in arcpy is arcpy.ListFields().
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
What is returned from arcpy.ListFields() is not field names, but a list of field objects which have accessible properties, including field name, type and length. These are printed above using string formatting. Getting a Python list of field names using list comprehension is straight out of the ArcGIS documentation. There are tons of great code samples there when you start sifting through it for specific tasks. I have learned to name the returned list of fields something like fieldList, and the returned list of names by naming it fieldNames so I can remember which data type I’m using.
Restricting the returned fields or field names
The following snippet illustrates ways you can restrict the returned fields: it’s always a good idea to limit the processing to what you actually need for the task at hand. For example, you can use a wildcard for field names in the middle parameter, or a field type in the third parameter. Another tidbit I found buried in a post by Drew Flater on an ArcGIS blog is how to prevent the return of required fields, such as OID or Shape, which can complicate things when using different data source types. Using list comprehension, he returns only those field names where the property “required” is false.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I have used Python dictionaries to compare the field characteristics of two feature classes. For example, I tested for fields of the same name but different lengths before appending. When the fields are automatically mapped by having the same name, the append operation will fail if the source string field is longer than the destination string field.
In the snippet below, two dictionaries are created using the field names and lengths as the key:value pairs. This means we can access the fields by name. Iterating through the destination feature class dictionary, the script looks for key matches (in this case, field names) in the source dictionary. Then, it can access the length of the field in each dictionary by referencing the key (field name) and compare the two integers.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters